
Introduction
Migrations and transformations can be messy, unsecure, unpredictable, costly, and painful if not done right. Especially when dealing with large numbers of applications and teams, the pain grows hand-in-hand with the complexity of the system and the organization.
To make migrations manageable and smooth, I developed the migration patterns approach. It’s the product of my experience in how software is built, run, operated, and migrated. It’s grounded in technical know-how of application development, platforms and hosting, a deep understanding of software development processes, and insight into what businesses actually want to achieve.
Since 2018, I’ve been deeply involved in migrations and transformations at Softwaredam. I’ve helped teams move, transform, and build small, large, and distributed applications across multiple hosting providers, clusters, and platforms — all centered around containers and Kubernetes.
Having also worked on mission-critical systems for years — as a developer, tester, architect, and coach — has given me the perspective needed to guide successful migrations.
That begin said, it is also important to remember that there is also no silver bullet for migrations, which fits 100%.
1. Determine Your Migration RTO
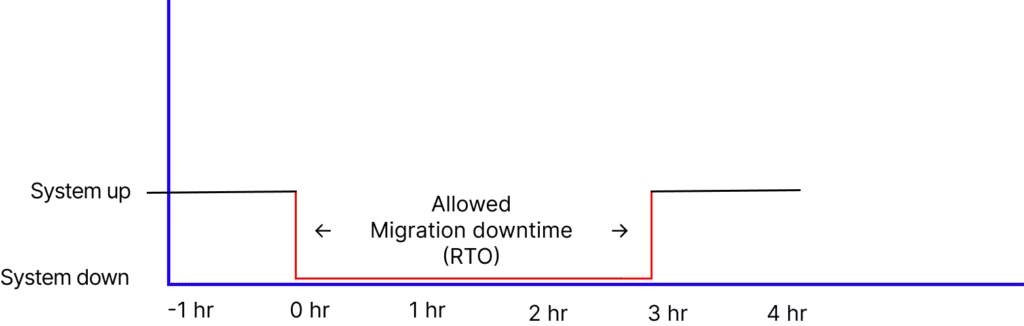
Recovery Time Objective (RTO) is the maximum acceptable downtime during production hours. It’s a key factor in determining the cost, complexity, and duration of a migration — and whether a big-bang, phased, or hybrid approach is most suitable.
Modern, highly available systems often have very short to no maintenance windows. In such cases, defining a migration-specific RTO becomes essential. It provides a measurable goal to work toward, alongside other objectives like cost savings or faster time to market.
Sometimes, the viability of an RTO needs to be tested. For example, if data synchronization takes at least five hours at zero-hour, then the business must accept that as the minimum RTO, plus some margin. DNS changes, database syncing, and integration with internal/external systems all impact this metric.
2. CI: Continuous Insight
In DevOps, Continuous Insight is often associated with Observability — monitoring metrics, logs, and traces to understand system behavior. But that’s not what we mean here.
In the context of migrations, Continuous Insight refers to maintaining a clear, evolving picture of the migration process itself. It’s about knowing what’s happening, what’s coming, and what’s already done.
Migrating hosting environments is like moving to a new house — you may not know everything you have, but you know you need to move it all.
Create a migration plan that includes:
- What needs to be prepared before migration
- What must be moved at zero-hour
- What should be cleaned up afterward
Keep this plan continuously updated. Its purpose is to give you and your organization control over the migration and serve as a communication tool for all stakeholders — developers, operations, managers, external partners, and even users.
At Softwaredam, we use a planning approach that provides continuous insight. We’ve seen firsthand how this helps businesses, teams, and consumers adapt more effectively. We build migration-specific Work Breakdown Structures (WBS) and even develop custom tools when needed.
One effective way to structure insight is by aligning it with DTAP environments (Development, Testing, Acceptance, Production). This helps teams understand where each application or component stands in the migration lifecycle. Another approach is to organize insight based on application streams — grouping related services or domains together to track progress and dependencies more clearly.
Additionally, we often break down insight into three key perspectives:
- IST — What is the current state? How much has already been migrated?
- Migration in Progress — What is actively being moved or transformed?
- SOLL — What is the desired end state? What has already arrived and been successfully placed
This triad helps teams and stakeholders visualize progress, identify bottlenecks, and stay aligned on the migration journey.

3. Compatibility First
Never assume your software is 100% compatible with the new environment. Test, observe, and make your applications forward and backward compatible.
This enables hybrid deployments and provides a fallback plan if something goes wrong during zero-hour. Compatibility testing is your safety net.
For example, when migrating containers to a new Kubernetes platform, you may encounter restrictions that weren’t present in your previous setup. Not all cluster providers allow containers to run with root privileges, which can break applications that rely on elevated access. Similarly, Ingress configurations may not be portable across providers — what works with NGINX might not be supported by Traefik, or vice versa. These differences can lead to unexpected failures if not accounted for early.
Always validate compatibility with:
- Runtime policies and security constraints
- Ingress controller behavior and configuration
- Resource limits and scheduling policies
- Networking and service discovery mechanisms
By proactively testing these aspects, you reduce surprises and ensure a smoother migration.
4. Test the Non-Functionals

Before moving your applications, test the non-functional requirements — performance, security, and scalability.
I’ve seen too many cases where teams deploy a “happy path” application and rush into zero-hour, only to be overwhelmed by operational issues. Helpdesks get flooded, trust is lost, and rollbacks become necessary.
When it comes to Kubernetes, make sure to test scalability under real-world conditions. Check whether the system scales as expected, both in terms of speed and reliability. For example:
- Does the cluster scale quickly enough to meet demand?
- Are new pods scheduled and started within acceptable timeframes?
- Is node availability consistent and predictable?
Kubernetes heavily relies on a stable network — so test it! Network instability can lead to cascading failures in service discovery, pod communication, and external integrations.
Simulate real-world scenarios to ensure your system can handle production-level demands.
5. Automate as Much as Possible

While automating build, test, and deployment is standard practice, I also recommend automating critical and repetitive parts of the migration. This ensures high security, quality, and performance.
Avoid using Word files or wiki pages for scripts — use Git for traceability and review. Examples of what to automate:
- File/data copying and synchronization
- Data conversion and transformation
- Non-functional testing
- Secret management (certificates, tokens, passwords)
- Configuration management
- DNS switching
Even outside of migration, automation of infrastructure provisioning, cluster management, and application deployment is already a best practice in modern software engineering.
Summary
Migrating to Kubernetes can be a complex and high-stakes endeavor, especially for large systems and teams. By focusing on measurable goals like RTO, maintaining continuous insight, ensuring compatibility, rigorously testing non-functional requirements, and automating critical processes, you can significantly reduce risk and improve outcomes. These five tips, drawn from years of hands-on experience, offer a practical foundation for a smooth and successful migration.
Need Help?
Don’t have the time or skills but still want a smooth migration? Contact us and get your free 30 min consult.